変数の型(Javaのデータ型)とは?
変数の型(Javaのデータ型)とは?【ゼロから始めるJavaの基礎~その11~】
前回は変数の使い方と、値の変更方法を学びましたね。
『変数を定義する際にはデータ型を指定する必要がある』というご紹介もしましたが、データ型について詳しい説明は省略しましたので、今回の記事でその部分をご紹介したいと思います。
型(データ型)とは?
Javaというプログラミング言語では、プログラムで扱われる数値やデータが何かしらの型に属している(型の情報を持っている)必要があります。
少し難しい表現になってしまいましたが、私達が日常生活で『整数』や『小数』、『ひらがな』や『カタカナ』を分けて使っているように、Javaで扱われるデータもそれぞれがどんな分類のデータなのか分かるようにしてあげる必要があるということです。
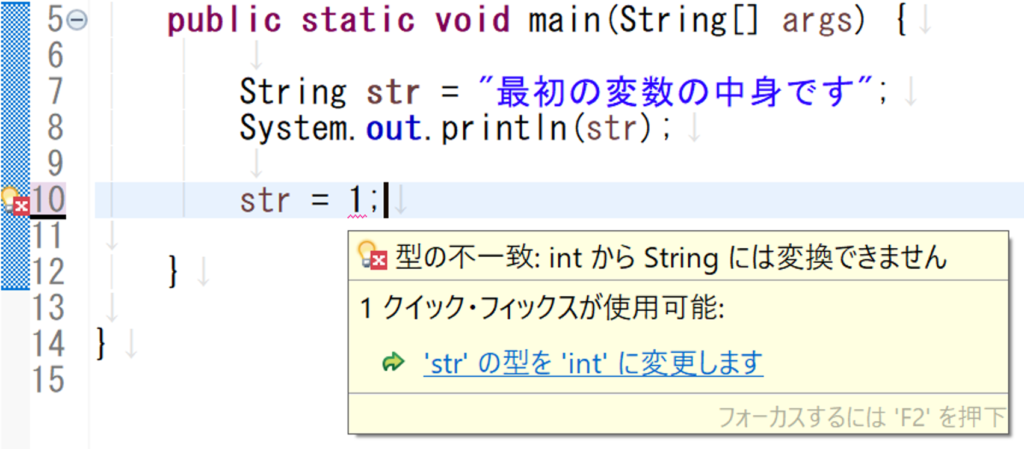
変数のトピックで、変数を初期化する際に型を指定しましたが、あれも「この変数は、この型のデータ専用の変数だよ!」ということを宣言するための記述で、異なるデータ型の値を代入することは出来ない仕組みになっているのです。
String型の変数に異なる型の値を再代入しようとするとエラーが発生する例
型の種類
少し前置きが長くなってしまいました。ここからはJavaにおける『型』にはどんなものがあるのかをご紹介します。
基本型(プリミティブ型)
その名の通り整数や小数など、データの基本となるような型を『基本型(プリミティブ型)』といいます。
| 種類 | 名称 | データの範囲 |
| 真偽値 | boolean | trueまたはfalse |
| 整数型 | byte | 1バイト整数(-128~127) |
| 整数型 | short | 2バイト整数(-32768~32767) |
| 整数型 | int | 4バイト整数(-2147483648 ~2147483647) ※約20億 |
| 整数型 | long | 8バイト整数(-9223372036854775808~ 9223372036854775807) |
| 浮動小数点型 | float | 4バイト浮動小数点数 |
| 浮動小数点型 | double | 8バイト浮動小数点数 |
| 文字型 | char | 2バイト文字(¥u0000~¥uffff) |
「基本型だけでこんなに種類があるのか…」と思った方もいるかも知れませんが、基本的によく使うのは『boolean型』、『int型』くらいです。小数を扱いたい場合も、だいたい『double型』を使っておけば問題ありません。
残りは「こんなのあったな〜」程度に覚えておき、使う必要が出た場面で復習しましょう。
また、整数型に4種類、小数点型に2種類データ型がありますね。「同じ整数を扱うのになぜ型を分ける必要があるのか」という疑問が出るかと思います。
深くまで解説するのは別の機会に譲るとして、簡単にまとめると、データ送信の効率性を上げる目的で使い分ける例が挙げられます。確実に1桁しか必要ないのに約20億も扱えるデータ領域を確保しておくのは効率が悪いですよね。
逆に金額を扱う場合など、20億を超える数値を扱う可能性が出る場合は『int型』ではなく『long型』を使うようにしないと扱えない数値が出てきてしまうため、状況に応じて用意するデータ型を調整しておく必要があります。
文字型の『char型』はデータの範囲が2バイト文字となっていますね。基本的には1文字だけを扱う型だと思ってください。ちなみに「キャラ型」と読みます。
char型のデータの範囲の括弧内に『¥u0000』という記述がありますが、これは『ユニコード』と呼ばれるものです。『¥u』に続く『16進数4桁』で1文字を表す文字コードのことです。『Unicode一覧』などのキーワードで検索すると一覧を見ることが出来ますので、興味のある方は調べてみてください。
参照型
鋭い方はお気づきだったと思いますが、変数についてのトピックで扱った『String型』がプリミティブ型には含まれていませんでした。
実は『String型』は『基本型』ではなく『参照型』という型に属しています。
基本型と参照型の違いについてはこちらの記事でご紹介をしていますが、少し込み入った内容ですので、小難しい話はとりあえず抜きにしたいという方は『String型は基本型ではない』ということだけは覚えておきましょう。
様々なデータ型が存在すること、よく使うデータ型や、それぞれの大まかな特徴はお判りいただけましたでしょうか?
ここでそれぞれのデータ型に値を代入し、それをコンソールに出力するサンプルを見てみましょう。
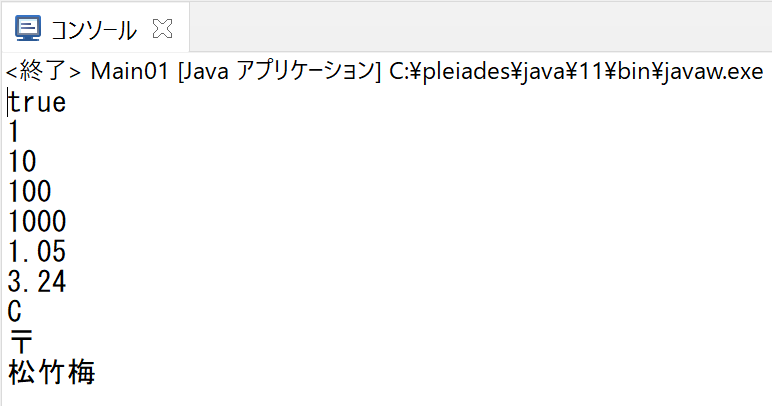
boolean boo = true;
System.out.println(boo);
byte b = 1;
System.out.println(b);
short s = 10;
System.out.println(s);
int i = 100;
System.out.println(i);
// long型はint型と区別するために末尾に『L(または小文字のl(エル))』を付与します。
long l = 1000L;
System.out.println(l);
// float型はdouble型と区別するために、末尾に『F(または小文字のf(エフ))』を付与します。
float f = 1.05F;
System.out.println(f);
double d = 3.24;
System.out.println(d);
// char型は文字の前後に『'』(シングルクォーテーション)を付与します。
char c = 'C';
// ユニコードを記述することもできます。
char uni = '\u3012';
System.out.println(c);
System.out.println(uni);
// String型は文字列の前後に『"』(ダブルクォーテーション)を付与します。
String str = "松竹梅";
System.out.println(str);実行結果
Javaのデータ型というのは数あるプログラミング言語の中でも細かく分けられており、厳しい制約がある部類であると言えます。
下記のように、異なるデータ型の値を代入しようとしたり、扱えるデータの範囲を超えている値を代入しようとするとコンパイルエラーが発生します。
// 型の不一致によるエラーが発生する例
boolean boo = 1;
int i = 3.24;
String str = 100;
// 扱えるデータの範囲を超えている例
byte b = 1000;
short s = 40000;
char c = 'CC';さて、データ型については何となく理解することが出来ましたでしょうか?正直なところ、なぜこんなにも細かくデータの型が分かれているのか分からないと感じている方も多いと思います。
最初はルールだと思って慣れていくしかありませんが、そのうち当たり前のことのように使い分けられるようになります。
型が厳密に分けられていることによって得られるメリットももちろんあります。一つには『型安全』というものが挙げられます。こちらについては少し応用的な内容にもなりますので機会があれば解説したいと思います。